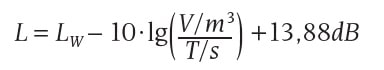Simulationen zur Planung der Lautsprecheranlage im Foyer der Messe Essen
von Anselm Görtz, Artikel aus dem Archiv vom
Akustisch schwierige Räume und sicherheitsrelevante Lautsprecheranlagen bedürfen einer soliden Planung. Die komplexen Zusammenhänge lassen sich mithilfe von Simulationsprogrammen erfassen und bewerten. Worauf es hier ankommt und wie man zu aussagekräftigen Ergebnissen kommt, erläutert dieser Beitrag am Beispiel des neuen Foyers der Messe Essen.(Bild: Jörg Küster)
Beim Neubau des Foyers Ost der Messe Essen sollte die ca. 2.500 Personen fassende Räumlichkeit mit einer Beschallungsanlage ausgestattet werden, die sowohl für Veranstaltungen aller Art wie auch für die Alarmierung in Notfallsituationen nutzbar ist. Die Eckdaten des Raumes sind eine Grundfläche von 1.780 m², eine Deckenhöhe von bis zu 12 m und ein Volumen von 22.300 m³. Die dreiseitige Außenfront ist komplett verglast, ebenso wie große Teile der Rückseite, die an die dahinter liegenden Büros und Konferenzräumen angrenzt. Mit einer variablen Inneneinrichtung wird der Raum sowohl als Eingangsportal für die Messe wie auch eigenständig als Saal für Veranstaltungen genutzt, wo die Hausanlage dann die Beschallung übernimmt oder ergänzend zu einer mobilen Anlage arbeitet.
Mit ein wenig Erfahrung erkennt man nur unschwer, dass eine gute Beschallung in diesem Raum nicht trivial ist und nach einer maßgeschneiderten Lösung verlangt. Für den Einsatz bei Veranstaltungen sollte die Anlage einen umfassenden Frequenzgang und eine gute Sprachverständlichkeit ähnlich wie in einem Hörsaal bieten, so dass man Vorträgen auch über einen längeren Zeitraum entspannt folgen kann. Die EN 60268-16 gibt dazu Empfehlungen in Form einer Tabelle mit zwölf anwendungsbezogenen Kategorien, welche Werte als STI für die Sprachverständlichkeit erreicht werden sollten. Für Vortragsräume liegt der empfohlene Wert bei 0,62, der für einen nur temporär für Vorträge genutzten Saal vielleicht ein wenig hoch gegriffen ist, aber eine gute Orientierung für den besetzten Zustand darstellt.
Ganz klar definiert sind die Werte beim Thema Sprachalarmierung. Seitens des Brandschutzkonzeptes ist eine Sprachalarmanlage (SAA) zur Alarmierung im Brandfall nach VDE 0833-4 gefordert. Dort wird ein STI Wert größer oder gleich 0,5 vorgegeben, der auch noch im nur schwach besetzten oder leeren Raum zu erreichen ist. Der Wert 0,5 ist dabei als Mittelwert aller Messpositionen abzüglich der Standardabweichung zu verstehen. Bei der Bestimmung der Werte sind zudem die pegelabhängige Maskierung und ein möglicher Störpegel zu berücksichtigen. Wer sich ein wenig in diesem Thema auskennt, weiß, dass diese Anforderungen für akustisch schwierige Räume hoch gesteckt und schwer zu erfüllen sind.
Deutlich leichter wird es, wenn eine Lautsprecheranlage nur als Elektroakustisches Notfallwarnsystem (ENS) definiert ist. Dabei wird der finale STI-Wert nach der seit 2017 gültigen EN 50849 als Mittelwert aller Messpunkt unter Vernachlässigung der schlechtesten 10 % und ohne Abzug der Standardabweichung berechnet. Für das Foyer der Messe Essen ist jedoch zum Zwecke der Alarmierung im Brandfall die VDE 0833-4 mit ihren strengeren Vorgaben anzuwenden.
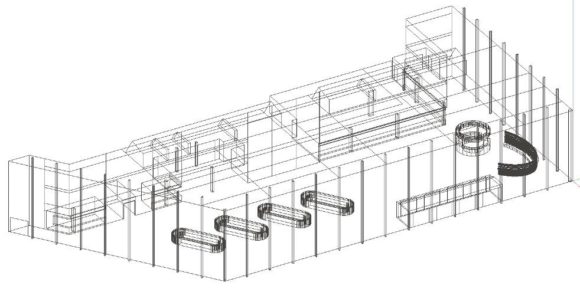
Die Größenordnung des Foyers in Kombination mit den Anforderungen legt es nahe, die Planung der Lautsprecheranlage mithilfe einer Simulation durchzuführen. Basis für eine aussagekräftige Simulation ist ein CAD-Modell des betreffenden Raumes, in dem alle akustisch relevanten Flächen vorhanden sein sollten. In Zeiten schneller Rechner darf das Modell dann auch etwas komplexer ausfallen, was nicht zuletzt auch optisch in der Präsentation besser aussieht. Das in ABB. 01 gezeigte Modell für das Foyer der Messe besteht aus 5.057 Flächen. Erstellt wurde das Modell mit Sketchup und anschließend im EASE Editor importiert. Diese Vorgehensweise ist die wohl am meisten genutzte, da der Modellbau für geübte CAD-Zeichner in Sketchup schnell und komfortabel von der Hand geht.
ABB. 01: Drahtgittermodell der Foyers. Hier werden jeder einzelnen Fläche die Materialdaten zugewiesen und weitere Elemente wie Lautsprecher oder Hörerflächen eingebaut. (Bild: Anselm Goertz)
Die hier genutzte Simulationssoftware EASE vom Berliner Büro AFMG (Ahnert, Feistel Median Group) ist für die Planung von Lautsprecheranlagen weltweit die meist genutzte Software. Fast alle Lautsprecherhersteller bieten ihre Daten für die EASE-Software im aktuellen GLL(Generic Loudspeaker Library)-Format an. Speziell bei raumakustischen Planungen sollten aber auch CATT Acoustic und Odeon nicht unerwähnt bleiben. Diese bieten einige Vorzüge, wenn es insbesondere um Auralisationen geht, können aber alles in allem nicht den Funktionsumfang und die großen Datenbanken für Projekte mit Lautsprecheranlagen bieten. Neben den universell einsetzbaren Simulationstools gibt es auch noch herstellerspezifische Programme, z. B. Boses Modeler oder Durans DDA, die primär für Produkte der betreffende Hersteller ausgelegt sind.
Ist das so genannte Drahtgittermodell erstellt, dann gilt es zunächst zu prüfen, ob der Raum in sich im Modell geschlossen ist und keine Löcher aufweist. Danach können den Flächen in Gruppen oder auch einzeln Materialdaten zugewiesen werden. Die Daten beschreiben frequenzabhängig das Absorptionsverhalten und können entweder einer Datenbank entnommen oder bei speziellen Akustikmaterialien von den Herstellern bezogen werden. ABB. 02 und ABB. 03 zeigen das fertige Modell in der Außenansicht und aus dem Innenraum heraus. Bei Letzterem besteht die Möglichkeit, mit dem „Walker“ durch den Raum zu laufen und sich virtuell umzuschauen, ähnlich, wie man es auch aus Sketchup kennt. Gegenüber dem einfachen Drahtgittermodell sind die Flächen jetzt farblich gekennzeichnet. In Hell- und Dunkelblau erkennt man die Glasflächen, in Hellbraun die Holzverkleidungen und in Hellgrau die Gipskarton(GK)-Decke, der hier eine entscheidende Funktion zukommt. Näheres dazu an späterer Stelle.
Nachhallzeit und Störpegel – die wichtigsten akustischen Parameter für die Planung!
Geht es um die Planung einer Beschallungsanlage, sind zwei akustische Parameter von größter Bedeutung: die Nachhallzeit als raumakustische Größe und der zu erwartende Störpegel durch Publikum, Maschinen oder andere Lärmquellen. Letzteres bestimmt, welchen Schalldruck eine Anlage erreichen muss, um sich hinreichend vom Störpegel abzuheben. Beide Größen sind stark frequenzabhängig und sollte daher möglichst für Oktav- oder besser noch Terzbänder angegeben werden. Einfache Einzahlparameter sind hier weniger geeignet, aber immer noch besser als gar nichts. An dieser Stelle gilt es zu betonen, dass die Planung einer Lautsprecheranlage ohne Kenntnis der Nachhallzeit und des zu erwartenden Störpegels nicht möglich ist! Existiert die Räumlichkeit schon, dann lassen sich die Werte meist durch eine Messung bestimmen. Befindet sich der Raum aber noch in der Bauphase, dann können die Werte nur rechnerisch ermittelt werden. Für die Nachhallzeit kann das mithilfe des Raumvolumens und der Oberfläche zusammen mit deren Absorptionsgrad anhand einfacher Formeln nach W.C. Sabine (1868–1919) oder C.F. Eyring (1889–1951) erfolgen. Diese Formeln gelten jedoch nur dann, wenn sich die absorbierenden Eigenschaften gleichmäßig auf den Flächen im Raum verteilen, was z. B. beim Einsatz einer Akustikdecke nicht der Fall ist, da sich ein Großteil der absorbierenden Fläche dann ausschließlich an der Decke befindet.
Eine zweite, etwas aufwendigere, aber deutlich genauere Methode ist die Simulation einer Nachhallzeitmessung im Modell. Man positioniert dort einige Punktschallquellen und berechnet für diese an verschiedenen Empfängerpositionen die Raumimpulsantworten, aus denen dann nach M. Schroeder (1926–2009) die Nachhallzeit frequenzabhängig berechnet werden kann.
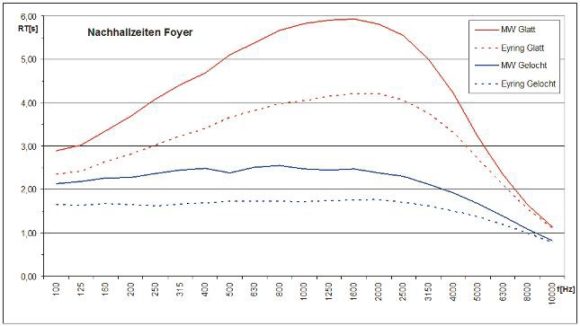
Für das Foyer der Messe wurden beide Arten der Berechnung durchgeführt. Im ersten Ansatz mit einer geschlossenen GK-Decke im Modellraum. Die so berechneten Nachhallzeiten – nach Eyring und über die Impulsantworten – sind als rote Kurven in ABB. 04 dargestellt. Die bis zu 2 s Differenz macht deutlich, wie wichtig eine korrekte Berechnung mithilfe der simulierten Nachhallzeitmessung ist. Unabhängig davon lässt die Kurve ein Maximum bei 1–2 kHz erkennen und einen deutlichen Abfall der Nachhallzeit zu den hohen und zu den tiefen Frequenzen. Bei hohen Frequenzen spielt in großen Räumen die Luftdämpfung eine merkliche Rolle ebenso wie die zu hohen Frequenzen hin zunehmende Absorption vieler Oberflächen. Etwas ungewöhnlich auf den ersten Blick ist der deutliche Rückgang bei tiefen Frequenzen. Dieser erklärt sich durch die großen Glasflächen, die bei tiefen Frequenzen absorbierend oder durchlässig (Transmission) wirken. Hinzu kommt noch die abhängte GK-Decke, die zu tiefen Frequenzen hin ebenfalls leicht absorbierend wirkt.
ABB. 04: Im Simulationsmodell berechnete Nachhallzeiten für eine geschlossene GK Decke (rot) und für die gelochte Variante (blau). Die durchgezogenen Linien zeigen die mit einer simulierten Nachhallzeitmessung berechneten Werte und die gestrichelten Linien die Werte aus einer vereinfachten Berechnung nach Eyring. (Bild: Anselm Goertz)
Basierend auf diesen ersten Berechnung wurde zur Reduzierung der Nachhallzeit vorgeschlagen, die Decke mit gelochten GK-Platten auszuführen, hinterlegt mit Vlies und Mineralwolle. Unabhängig von der Beschallung erschien eine Nachhallzeit von bis zu 6 s auch für das akustische Klima im Raum als nicht akzeptabel – hier kommt dann erstmals der Störpegel mit ins Spiel. Bei gleichem Schallleistungspegel einer Lärmquelle steigt der Lärmpegel im Raum mit jeder Verdopplung der Nachhallzeit um 3 dB. Viele Personen in einem Raum erzeugen durch ihre Unterhaltung einen gewissen Störpegel. Je höher dieser ist, umso lauter sprechen die Personen (Lombard-Effekt), und der Lärm schaukelt sich weiter auf. Jeder kennt diesen Effekt aus Restaurants, die sich in halligen Räumen befinden, wo häufig selbst mit dem direkten Tischnachbarn kaum noch ein Gespräch möglich ist.
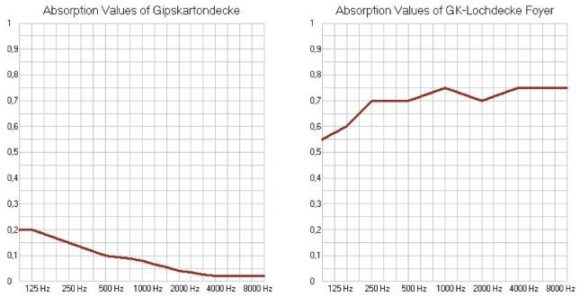
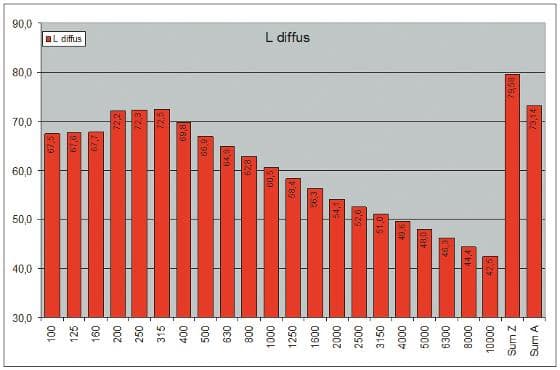
ABB. 05: Absorptionsverhalten einer geschlossenen Gipskartondecke (links) im Vergleich zu einer gelochten GK-Platte (rechts) mit hinterlegtem Vlies und einer Auflage aus Mineralwolle. (Bild: Anselm Goertz)
Wie groß der Unterschied zwischen normalen GK-Platten und akustisch wirksamen, gelochten GK-Platten ist, zeigt ABB. 05. Die mit hinreichendem Abstand zur Betondecke angebrachten und mit Mineralwolle hinterlegten gelochten Platten absorbieren breitbandig ca. 70 % des auftreffenden Schalls. Im Modell wurde daher die gesamte Deckenfläche von ca. 1.800 m², mit Ausnahme der beiden verglasten Dachaufbauten von jeweils 75 m², als gelochte GK-Platte angenommen. Die blauen Kurven aus ABB. 04 lassen die Wirkung erkennen. Die Nachhallzeit im mittleren Frequenzbereich sinkt von fast 6 s auf 2,5 s, und der Verlauf insgesamt wird gleichmäßiger.
Um auch den zu erwartenden Störpegel zu bestimmen, muss zunächst geklärt werden, welche Störpegelquellen es gibt. Im Falle einer Alarmierung würden bei einer Veranstaltung alle Fremdbeschallungen umgehend automatisch abgeschaltet, so dass, wie auch im normalen Messbetrieb, primär die dort anwesenden Personen als Störquelle bleiben. Geht man von den maximal möglichen 2.400 Personen aus, von denen die Hälfte mittellaut spricht, lässt sich der Störpegel zusammen mit dem Raumvolumen und der Nachhallzeit einfach ausrechnen. Als Störspektrum wird jeweils zur Hälfte von männlichen und von weiblichen Stimmen ausgegangen. Mittellautes Sprechen entspricht einem Schallleistungspegel von 68 dBA. Das entspricht unter Berücksichtigung der Richtwirkung eines Sprechers einem Schalldruckpegel von ca. 63 dBA in Sprechrichtung in 1 m Abstand. Aus diesen Werten, zusammen mit den Sprachspektren und der frequenzabhängigen Nachhallzeit T sowie dem Raumvolumen V, kann der Störpegel und dessen spektrale Zusammensetzung (ABB. 06) nach folgender Formel berechnet werden:
1.200 Quellen mit je 68 dBA ergeben in der Summe einen Schallleistungspegel LW von 98,8 dBA. Das Volumen beträgt 22.300 m³ und die mittlere Nachhallzeit 2,4 s. Der so berechnete Störpegel beträgt 73 dBA. Ohne die gelochte GK-Decke läge der Wert bei 76,4 dBA. Diese Art der Berechnung liefert eine gute Abschätzung für den zu erwartenden Störpegel, wenn es keine anderen Geräuschquellen wie z. B. Entrauchungsanlagen gibt. Die Berechnung liefert einen relativ sicher abgeschätzten Wert, da bei der eingesetzten Nachhallzeit die absorbierende Wirkung des Publikums nicht berücksichtigt, sondern weiter mit den Werten der leeren Halle gerechnet wurde. Für den Alarmierungspegel bedeuten die 73 dBA Störpegel, dass für die Sprachansage ein Wert von mindestens 83 dBA, besser noch 88 dBA erreicht werden sollte.
ABB. 06: Störpegelabschätzung für 2.400 Personen im Foyer, von denen sich die Hälfte mittellaut mit 68 dBA Schallleistungspegel unterhält. Der Gesamtpegel liegt dann bei ca. 73 dBA. (Bild: Anselm Goertz)
Für eine Anlage, die als SAA nach VDE 0833-4 definiert ist, bedarf es der durchgängigen Verwendung von EN54-zertifizierten Komponenten. Für die Lautsprecher bedeutet das EN54- 24 und für die Zentralentechnik EN54-16. Da sich die zu beschallenden Personen im Messe- Foyer auf einer Ebene befinden, bieten sich für einen hohen Raum, wie es hier der Fall ist, Lautsprecherzeilen an, die die Beschallung möglichst gut auf diesen Bereich konzentrieren und den restlichen Raum so wenig wie möglich anregen. Auf aktive DSP-Zeilen sollte verzichtet werden – zum einen wegen der erforderlichen Sondergenehmigung zum Betrieb in einer SAA nach VDE 0833-4, zum anderen wegen des erhöhten Aufwandes für die Ersatzenergieversorgung mit dezentral angeordneter Elektronik.
Die Wahl für die Beschallung des Foyers fiel auf passive 2-Wege-Zeilen des Typs SR-S4 von TOA und einige kleine Deckenlautsprecher, ebenfalls von TOA, zur Versorgung der Randbereiche wie Garderoben oder Übergänge zur den Büros und Toiletten. Die passiven, 90 cm langen Zeilen sind pro Einheit mit acht Tieftönern und 24 Hochtönern bestückt und können bei Bedarf kaskadiert werden. Zur besseren Abdeckung der Bereiche nahe an der Zeile gibt es auch eine leicht gebogene Variante mit 10° Krümmung. Für das Foyer wurden insgesamt sieben kombinierte Zeilen aus je einer geraden und einer gekrümmten Einheit eingesetzt. Jede Einheit wurde separat mit einem 100 V/200 W-Übertrager bestückt. Die Kombination in dieser Form ist EN54-24 zertifiziert und kann in Sprachalarmanlagen nach VDE 0833-4 eingesetzt werden. Alternativ zu den Zeilenlautsprechern wurden die Berechnungen auch noch für einen klassischen Point- Source-Lautsprecher durchgeführt, der hier als Vergleich zur Veranschaulichung für die richtige Auswahl der Lautsprecher dienen soll. Als Montagepunkte für die Lautsprecher boten sich in der voll verglasten Front nur die Stahlträger an. Die Positionen waren somit bereits weitgehend bestimmt.
Bevor man sich mit einer Simulation befasst, wäre zunächst die Frage zu stellen, welche Werte eine aussagekräftige Simulation liefern muss und mit welchen Grundeinstellungen diese zu berechnen sind. Im ersten Arbeits-schritt ist das eine Direktschallpegelverteilung über der Fläche. Diese ist besonders für die höheren Frequenzbänder wichtig, da die Lautsprecher hier stärker bündeln, aber trotzdem eine vollständige Abdeckung der relevanten Hörerflächen mit den für die Sprachverständlichkeit wichtigen hohen Frequenzen gegeben sein sollte. Als Anregungssignal wird für diese Simulation ein Pinknoise genutzt, um alle Frequenzbänder gleichermaßen anzuregen.
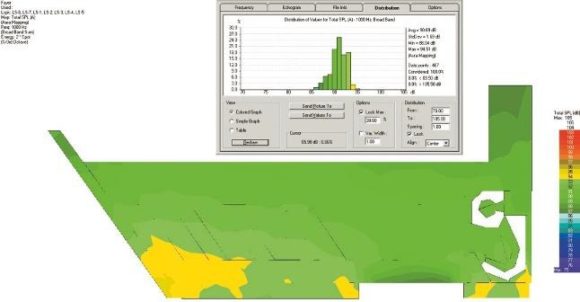
ABB. 07 und ABB. 08 zeigen dazu die Berechnungen des Direktschallpegels (DSPL) für die Point-Source- und für Line-Source-Lautsprecher. Die Darstellung erfolgt als Mapping über der Grundfläche. Gut zu erkennen sind die etwas schwächer ausgeleuchteten Randbereiche an den oberen Enden, was sich zusammen mit dem Diffusfeld in der Darstellung des Gesamtschallpegels (TSPL) aber wieder relativiert. Außer einer etwas gleichmäßigeren Verteilung sind im Direktschall-Mapping noch keine großen Unterschiede der beiden Lautsprechertypen zu erkennen. Der Raum spielt zu diesem Zeitpunkt noch keine Rolle. Bislang geht es nur um eine gute Direktschallabdeckung für mittlere und hohe Frequenzen.
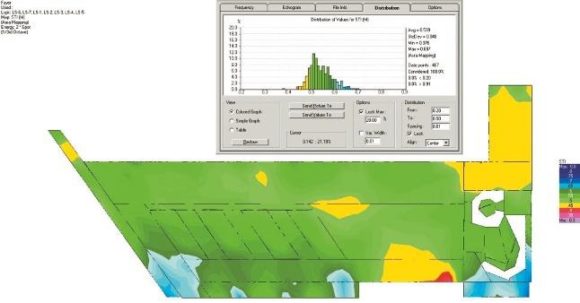
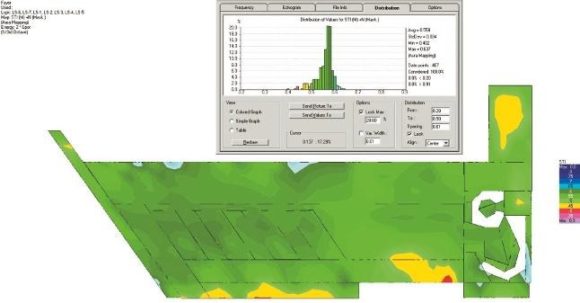
Interessanter wird es dann beim Thema Sprachverständlichkeit, die im Folgenden als STI-Wert für vier Konstellationen als Mapping und als Distribution berechnet wurde. Neben den beiden Lautsprechertypen (Point- und Line-Source) wurde auch noch die Decke des Foyers zwischen glatten und gelochten GK-Platten variiert. Der STI wurde dazu zunächst ohne Berücksichtigung der Maskierung und des Störpegels berechnet. Die Berechnung erfolgte im EASE mithilfe der Aura- Methode, einer kombinierte Spiegelquellen- und Strahlenverfolgungsmethode für Impulsantworten mit einer Länge von 3,3 s für jeweils 467 Punkte auf der Hörerfläche. Die Länge der berechneten Impulsantworten sollte dabei mindestens 50 % der Nachhallzeit betragen, was hier gut erfüllt ist. Schon das erste Ergebnis macht die schwierige Lage deutlich. Das Mapping in ABB. 09 für Point-Source- Lautsprecher im Foyer mit glatter Decke prognostiziert einen STI-Mittelwert von 0,36 mit einer Standardabweichung von 0,05 und somit einen Gesamtwert von 0,31, der weit unterhalb der Anforderung liegt. So geht es also nicht.
Im nächsten Schritt wurden bei unveränderter Raumakustik die Line-Source-Lautsprecher anstelle der Point-Sources eingesetzt. In ABB. 10 wird damit eine deutliche Verbesserung auf einen STI-Mittelwert von jetzt 0,47 mit einer Standardabweichung von 0,04 erreicht. Der Gesamtwert beträgt jetzt 0,43, was zwar immer noch nicht ausreichend, aber schon ein großer Schritt in die richtige Richtung ist. In der subjektiven Wahrnehmung wäre der Unterschied schon sehr deutlich.
Nun kommt die gelochte GK-Decke ins Spiel, die jetzt schon mit den Point-Source- Lautsprechern einen Gesamtwert für den STI von 0,49 liefert (ABB. 11). Man könnte jetzt geneigt sein die 0,49 noch ein wenig „hinzubiegen“, und schon wären die geforderten 0,5 erreicht und das sogar mit den einfacheren und günstigeren Point-Source-Lautsprechern.
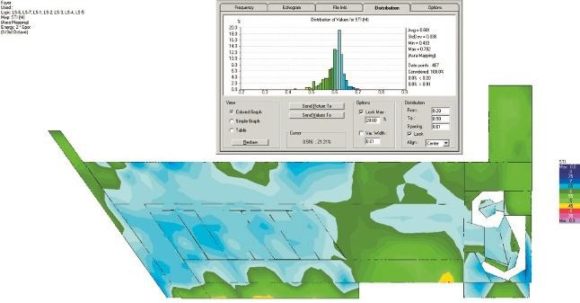
ABB. 11: STI als Mapping und Distribution für Point-Source-Lautsprecher bei gelochter GK-Decke mit einem Mittelwert von 0,54 und einer Standardabweichung von 0,05 entsprechend einem Gesamtwert von 0,49. (Bild: Anselm Goertz)
Dabei wäre aber noch nicht berücksichtigt, dass streng nach EN 60268-16 Ausgabe 2011 auch noch die Maskierung einzubeziehen ist, die den Wert ihrerseits auch wieder reduziert. Vernachlässigbar ist die Maskierung nur bei Sprachpegeln von 80 dBA oder weniger. Letzteres ist hier mit einem Alarmierungspegel von 88 dBA oder mehr nicht der Fall. Die Maskierung kann zudem nicht als einfacher Faktor eingerechnet werden, sondern muss zusammen mit dem Signalspektrum detailliert berechnet werden. Sieht man es ganz eng, dann müsste auch der Störpegel noch mit einbezogen werden. Kurzum, es werden noch Reserven benötigt. Um einen Wert von 0,49 gesund zu beten, wird es daher nicht reichen. Die notwendigen Reserven bietet dann die vierte Variante mit Line-Source-Lautsprechern und gelochter GK-Decke. ABB. 12 zeigt dazu das Mapping und die Distribution mit einem Gesamtwert von 0,56, jedoch noch ohne Maskierung und ohne Störpegel.
ABB. 12: STI als Mapping und Distribution für Line-Source-Lautsprecher bei gelochter GK-Decke mit einem Mittelwert von 0,6 und einer Standardabweichung von 0,04 entsprechend einem Gesamtwert von 0,56. (Bild: Anselm Goertz)
Die korrekte Berechnung der Maskierung setzt voraus, dass die Simulation mit einem Sprachspektrum berechnet wird, das in EASE als Filter in der Lautsprecher-GLL einzustellen ist. Da für ein Sprachsignal nach VDE 0833-4 zudem ein Crestfaktor (Verhältnis Spitzenwert zu Effektivwert) von 12 dB zu berücksichtigen ist, muss die Berechnung mit entsprechendem Headroom durchgeführt werden. Geht man davon aus, dass der ansteuernde Verstärker pro Lautsprecher mit einem Sinussignal 200 W zu liefern in der Lage ist, entspricht das einer Peakleistung von 400 W, bei der der Verstärker an seine Grenzen stößt. Gleichermaßen mit einem Sprach- oder STIPA-Testsignal mit 12 dB Crestfaktor voll ausgesteuert, beträgt die Peakleistung auch 400 W, die mittlere Leistung jedoch nur 25 W (12 dB entspricht einem Leistungsfaktor 16). Geht man jetzt kurz auf die akustische Seite, dann wird hier als relevanter Pegel bei einer Messung zur Sprachverständlichkeit der Leq und somit ein Mittlungspegel gemessen. Der Leq des Schalldrucks ist das akustische Äquivalent zum Mittelwert der Leistung (average power) bzw. zum Effektivwert der Spannung auf der elektrischen Seite.
ABB. 13: Gesamtschallpegel (TSPL) berechnet als A-bewerteter Mittlungspegel LAeq für ein Sprachsignal mit 12 dB Crestfaktor. (Bild: Anselm Goertz)
Möchte man also wissen, wie hoch der tatsächlich messbare Leq-Wert mit einem Sprachersatzrauschen oder dem STIPA-Testsignal sein wird, müssen wir in der Simulation einen Headroom von zusätzlichen 9 dB einstellen. Die 9 dB entsprechen dem Verhältnis der Verstärker Nennleistung von 200 W in Relation zur maximal möglichen mittleren Leistung von 25 W mit einem 12 dB Crestfaktor-Signal. Dieser Zusammenhang mag zunächst verwirren, ist aber von großer Wichtigkeit. Denn sonst passiert es schnell, dass bei der ersten Messung einer Anlage plötzlich 9 dB weniger auf dem Pegelmesser stehen, als ursprünglich berechnet wurden.
Mit 12 dB Crestfaktor und einem Sprachspektrum nach EN 60268-16 berechnet, ergibt sich für die Variante 4 mit Line-Source-Lautsprechern und gelochter GK-Decke ein Maximalpegel als LAeq von 91 dBA, womit ein hinreichender Störabstand auf jeden Fall gewährleistet wäre.
Für eine finale Berechnung der Sprachverständlichkeit werden im EASE jetzt noch die Optionen Maskierung und Noise aktiviert. ABB. 14 zeigt das so berechnete STI-Mapping mit Distribution. Der Gesamtwert liegt bei 0,53. Ohne Noise, aber mit Maskierung kommt man auf einen Gesamtwert von 0,54. Diese Ergebnisse bieten auch unter Berücksichtigung von gewissen Toleranzen eine hinreichende Sicherheit, den geforderten Wert von 0,5 später auch in der Realität einzuhalten.
ABB. 14: STI als Mapping und Distribution berechnet mit Maskierung und Störpegel für Line-Source-Lautsprecher bei gelochter GK-Decke mit einem Mittelwert von 0,56 und einer Standardabweichung von 0,03 entsprechend einem Gesamtwert von 0,53. (Bild: Anselm Goertz)
Fassen wir die Voraussetzung für eine aussagekräftige Simulation noch einmal zusammen:
Die Simulationen sind mit einem passenden Signalspektrum zu berechnen – für Aussagen zur Gleichmäßigkeit und zum Frequenzgang mit einem Pinknoise und für die STI Werte und Maximalpegel mit einem Sprachspektrum.
Der entsprechende Crestfaktor der Signale ist für die Bestimmung des Maximalpegels als Headroom unbedingt zu berücksichtigen.
Berechnungen zur Sprachverständlichkeit sollten mit der Aura- Methode über die Impulsantworten durchgeführt werden.
Die Länge der berechneten Impulsantworten sollte mindestens 50 % der zu erwartenden Nachhallzeit betragen, besser noch mehr.
Die Mappings sind mit einer angemessenen Auflösung zu berechnen.
Bei der STI-Berechnung sind Maskierung und Störpegel zu berücksichtigen.
Alle vorab beschriebenen Parameter und Einstellungen sind unbedingt zusammen mit den Simulationsergebnissen zu dokumentieren.
Unabhängig von diesen Einstellungen gibt es in den Simulationsprogrammen immer noch einige Quellen für Fehler und Ungenauigkeiten, die man im Hinterkopf haben sollte. Da sind zum einen die Lautsprecherdaten, wo man gut daran tut, diese auf Plausibilität zu prüfen oder noch besser mit Messwerten aus Datenblättern oder Testberichten zu vergleichen. Gleiches gilt für die Absorberdaten, die unter optimalen Laborbedingungen ermittelt werden, wo durch den Kanteneffekt zu hohe Absorptionswerte entstehen können. Hinzu kommt, dass in der Realität meist nicht die komplette Fläche absorbierend wirkt, da es auch noch Einbauten in den absorbierenden Flächen durch Lampen, Lüftungen etc. geben kann. Ein guter Ansatz ist daher, die Herstellerdaten für die absorbierenden Materialien um 10 % zu reduzieren. Vorsicht ist auch geboten, wenn die Absorber nicht hinreichend dem Schallfeld exponiert sind und so nicht ihre volle Wirkung entfalten können.
Weitere Fehlerquellen sind grundsätzliche Schwächen der Simulationsprogramme, wenn es um Beugungseffekte und Schallstreuung geht. Die Beugung wird gar nicht berücksichtigt und die Streuung nur rudimentär. Bei großen Projekten mit sehr vielen Lautsprechern und großen Flächen kommen noch softwarespezifische Probleme mit der Speicherverwaltung und Prozessorauslastung hinzu, die dem Planer die Arbeit manchmal ein wenig erschweren.
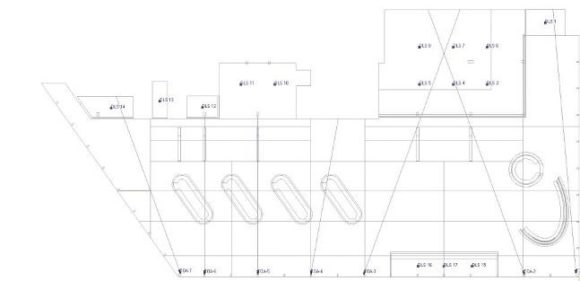
ABB. 15: Grundriss des Foyers mit Lautsprecherpositionen. Zusätzlich wurden zu den Hauptlautsprechern für die Bereiche der Garderoben und der abgehenden Gänge noch Deckenlautsprecher (DLS) vorgesehen. (Bild: Anselm Goertz)
ABB. 15 zeigt final noch den Grundriss mit der Lautsprecheranordnung, so wie sie auch umgesetzt wurde. Es gibt sieben 1,8 m lange Zeilen aus je einem geraden und einem gekrümmten TOA SR-S4-Element und noch 15 zusätzliche Deckenlautsprecher, die den Windfang am Eingang, die Garderoben und die Gänge zu den Toiletten und Büros versorgen. Details und Fotos zur Installation finden sich im Beitrag „Neues Foyer Ost der Messe Essen“.
Simulationsprogramme sind heute ein kaum noch wegzudenkendes Werkzeug bei der Planung von Raumakustik und Beschallungsanlagen. Häufig sind die Fälle grenzgängig oder aus der Erfahrung alleine nicht abzuschätzen, und mithilfe einer Simulation kann dann Klarheit geschaffen werden. Viele Ausschreibungen fordern zudem ohnehin eine Simulation der angebotenen Beschallungslösung, mit deren Hilfe dann die entsprechende Funktion nachgewiesen werden soll. Letzteres gelingt jedoch nur dann, wenn alle Voraussetzungen vom Modellbau über die Lautsprecher- und Materialdaten bis hin zu den Parametern der Berechnung stimmen bzw. sinnvoll gewählt werden. Und das geht nicht mal eben nebenbei, sondern fordert Expertenwissen und Zeit. Beides kostet dann konsequenterweise auch Geld, wenn einige Arbeitstage für ein aussagekräftiges Ergebnis mit Gutachten aufgewendet werden müssen. Als Auftraggeber sollte man sich dessen bewusst sein und diese Aufgabe vorzugsweise einem neutralen Planungsbüro überlassen. Die Kosten dafür sind im Vergleich zu den Gesamtkosten einer solchen Installation meistens eher gering.